AI Video Generation Models
 |
| Welcome to the Matrix |
Hunyuan Video Generation
 |
| Hunyuan GPU Requirements for generating 129 frames |
-------------------------------------------------------------------------------------------------
Hunyuan Video GPU Poor version by DeepBeepMeep
- Reduce greatly the RAM requirements and VRAM requirements
- 5 profiles in order to able to run the model at a decent speed on a low end consumer config (32 GB of RAM and 12 VRAM) and to run it at a very good speed on a high end consumer config (48 GB of RAM and 24 GB of VRAM)
- Support multiple pretrained Loras with 32 GB of RAM or less
- Switch easily between Hunyuan and Fast Hunyuan models and quantized / non quantized models
--------------------------------------------------------------------------------------------------------------------
Wan 2.1 Video Generation
- 👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
- 👍 Supports Consumer-grade GPUs: The T2V-1.3B model
requires only 8.19 GB VRAM, making it compatible with almost all
consumer-grade GPUs. It can generate a 5-second 480P video on an RTX
4090 in about 4 minutes (without optimization techniques like
quantization). Its performance is even comparable to some closed-source
models.
- 👍 Multiple Tasks: Wan2.1 excels
in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and
Video-to-Audio, advancing the field of video generation.
- 👍 Visual Text Generation: Wan2.1
is the first video model capable of generating both Chinese and English
text, featuring robust text generation that enhances its practical
applications.
- 👍 Powerful Video VAE: Wan-VAE
delivers exceptional efficiency and performance, encoding and decoding
1080P videos of any length while preserving temporal information, making
it an ideal foundation for video and image generation.
-----------------------------------------------------------
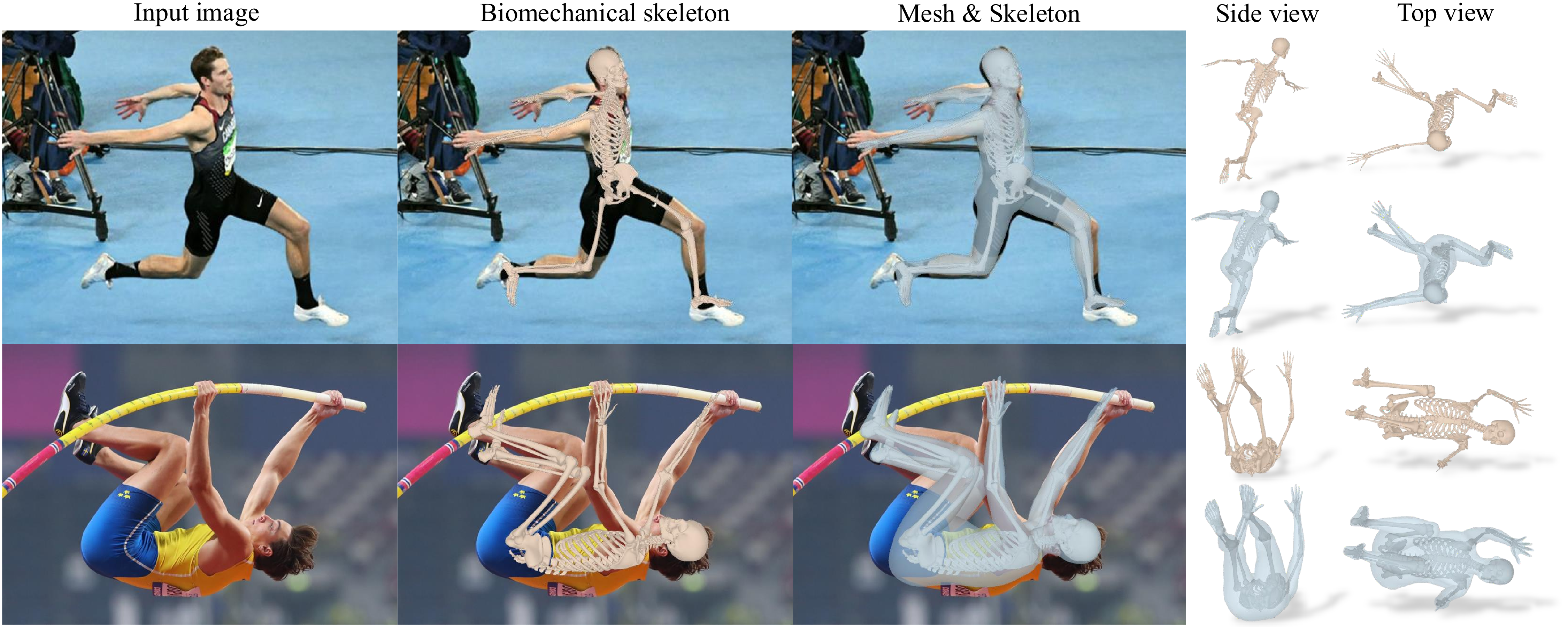
Reconstructing Humans with a
Biomechanically Accurate Skeleton
-----------------------------------------------------------
AnimeGamer: Infinite Anime Life Simulation with Next Game State Prediction
----------------------------------------------------------- SkyReels-A2: Compose Anything in Video Diffusion Transformers
Give reference images + text prompt to get video
-----------------------------------------------------------
Bytedance : DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance
-----------------------------------------------------------
Alibaba VACE
-----------------------------------------------------------
Meta - MoCha
Towards Movie-Grade Talking Character Synthesis
 |
This isn't real?
|







Comments