Note:
This page contains a large number of images and videos. Due to the size and quantity of the media, it may take some time for the content to fully load. Some images and videos may not appear immediately but will load shortly.
May not work on Mobile
Meta Segment Anything SAM:-
https://segment-anything.com/
The Segment Anything Model (SAM) produces high quality
object masks from input prompts such as points or boxes, and it can be
used to generate masks for all objects in an image. It has been trained
on a dataset of 11 million images and 1.1 billion masks, and has strong zero-shot performance on a variety of segmentation tasks.
SAM 2: Segment Anything in Images and Videos
https://ai.meta.com/sam2/
https://github.com/facebookresearch/sam2
Segment Anything Model 2 (SAM 2) is a
foundation model towards solving promptable visual segmentation in
images and videos. We extend SAM to video by considering images as a
video with a single frame. The model design is a simple transformer
architecture with streaming memory for real-time video processing. We
build a model-in-the-loop data engine, which improves model and data via
user interaction, to collect our SA-V dataset,
the largest video segmentation dataset to date. SAM 2 trained on our
data provides strong performance across a wide range of tasks and visual
domains.

Grounded SAM
https://github.com/IDEA-Research/Grounded-Segment-Anything
We plan to create a very interesting demo by combining Grounding DINO and Segment Anything
which aims to detect and segment anything with text inputs! And we will
continue to improve it and create more interesting demos based on this foundation.
And we have already released an overall technical report about our project on
arXiv, please check Grounded SAM:
Assembling Open-World Models for Diverse Visual Tasks for more details.
🔥 Grounded SAM 2 is released now, which combines Grounding DINO with SAM 2 for any object tracking in open-world scenarios.
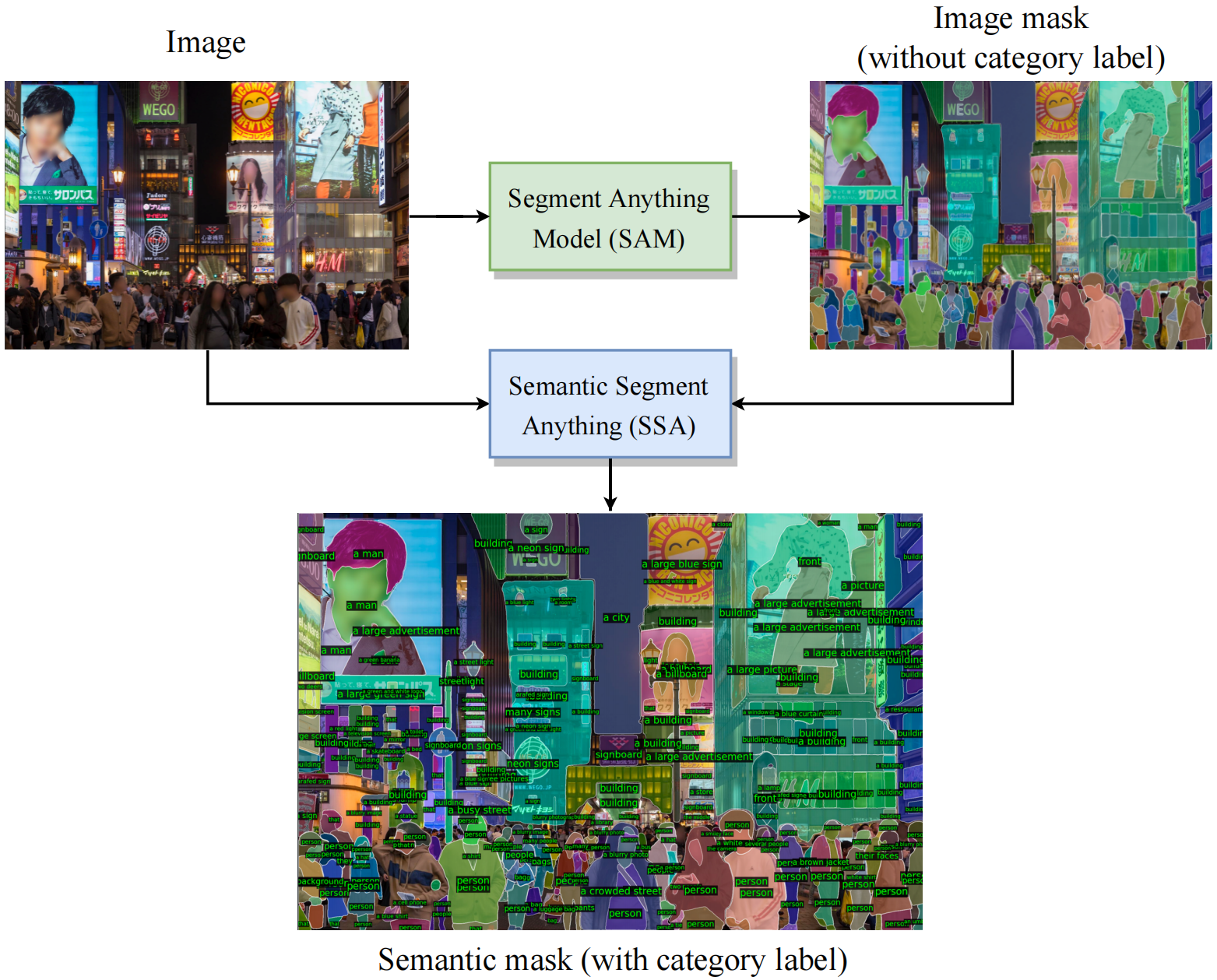
Semantic Segment Anything
https://github.com/fudan-zvg/Semantic-Segment-Anything
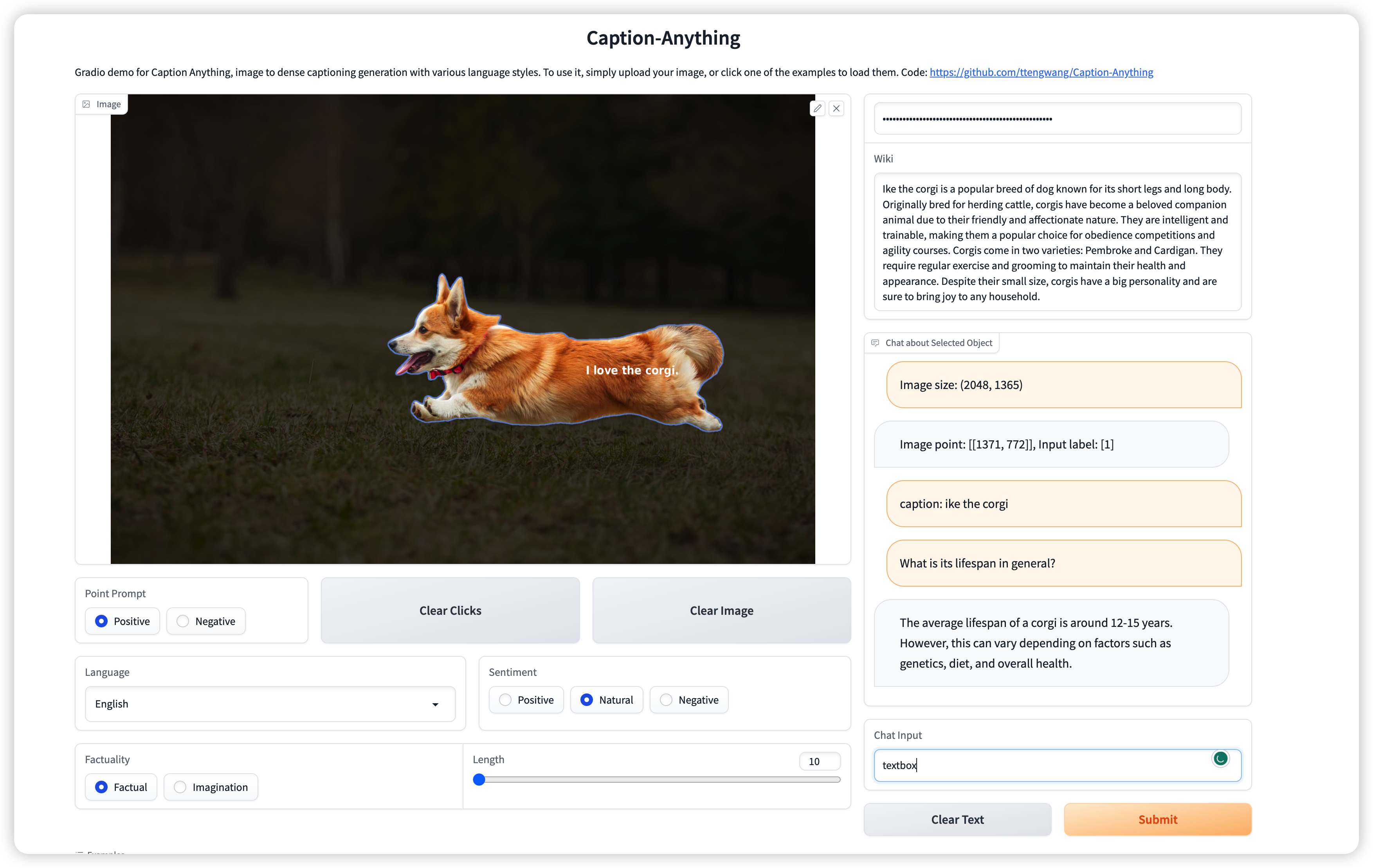
Caption Anything
https://github.com/ttengwang/Caption-Anything
Caption-Anything
is a versatile image processing tool that combines the capabilities of Segment Anything,
Visual Captioning, and ChatGPT.
Our solution generates descriptive captions for any object within an image,
offering a range of language styles to accommodate diverse user preferences. It
supports visual controls (mouse click) and language controls (length,
sentiment, factuality, and language).
Inpaint Anything:
https://github.com/geekyutao/Inpaint-Anything
Users can select any object in an image by clicking on it. With powerful
vision models, e.g., SAM,
LaMa and Stable Diffusion (SD),
Inpaint Anything is able to remove the object smoothly (i.e., Remove
Anything). Further, prompted by user input text, Inpaint Anything can fill
the object with any desired content (i.e., Fill Anything) or replace
the background of it arbitrarily (i.e., Replace Anything).
📜 News
[2023/9/15] Remove
Anything 3D code is available!
[2023/4/30] Remove
Anything Video available! You can remove any object from a video!
[2023/4/24] Local
web UI supported! You can run the demo website locally!
[2023/4/22] Website
available! You can experience Inpaint Anything through the interface!
[2023/4/22] Remove
Anything 3D available! You can remove any 3D object from a 3D scene!
[2023/4/13] Technical report on arXiv
available!
Remove Anything:
https://github.com/geekyutao/Inpaint-Anything?tab=readme-ov-file#-remove-anything
Remove Anything 3D
👀SEEM: Segment Everything
Everywhere All at Once
https://github.com/UX-Decoder/Segment-Everything-Everywhere-All-At-Once
We introduce SEEM that can Segment Everything Everywhere with Multi-modal
prompts all at once. SEEM allows users to easily segment an image using prompts
of different types including visual prompts (points, marks, boxes, scribbles
and image segments) and language prompts (text and audio), etc. It can also
work with any combination of prompts or generalize to custom prompts!
Towards Segmenting
Anything That Moves
https://github.com/achalddave/segment-any-moving
TRACK anything
https://github.com/gaomingqi/Track-Anything
3D BOX SAM
https://github.com/dvlab-research/3D-Box-Segment-Anything
Segment
Anything and its following projects focus on 2D images. In this
project, we extend the scope to 3D world by combining Segment
Anything and VoxelNeXt.
When we provide a prompt (e.g., a point / box), the result is not only 2D
segmentation mask, but also 3D boxes.
The core idea is that VoxelNeXt
is a fully sparse 3D detector. It predicts 3D object upon each sparse voxel. We
project 3D sparse voxels onto 2D images. And then 3D boxes can be generated for
voxels in the SAM mask.
Segment Anything 3D
https://github.com/Pointcept/SegmentAnything3D
We extend Segment Anything
to 3D perception by transferring the segmentation information of 2D images to
3D space. We expect that the segment information can be helpful to 3D
traditional perception and the open world perception. This project is still in
progress, and it will be embedded into our perception codebase Pointcept. We very much
welcome any issue or pull request.
E2FGVI (CVPR 2022) Towards An End-to-End Framework for Flow-Guided Video Inpainting
https://github.com/MCG-NKU/E2FGVIThis repository contains the official implementation of the following paper:
Towards An End-to-End Framework for Flow-Guided Video Inpainting
------------------------------------------
Segment Any Motion in Videos

























Comments